代码小白用WorkBuddy轻松爬取网站信息并存储
- 2026-05-13 18:10:11
需求描述
应用WorkBuddy实现需求
2.1 先获取新闻标题和时间
2.2 获取文章内容

背景:我的大学老师目前正在从事科研,有获取某个网站信息的需求,问我能不能帮忙下载一下数据。
需求:下载https://www.ccdi.gov.cn/xsxcn/index.html网站上的新闻标题、时间,如果能把每个新闻的内容都能搞出来就更好了。
之前有尝试用trae实现该需求,反馈网站有严格的反爬虫机制,只能获取第一页的内容,没想到WorkBuddy竟然这么轻松地就完美实现了需求。

1 先获取新闻标题和时间
由于我也是初次使用WorkBuddy,所以我抱着试试看的心态进入了claw模块,想着先简单点,不获取文章内容,只获取新闻标题和时间。
指令如下:https://www.ccdi.gov.cn/xsxcn/index.html 帮我爬取这个网站上的新闻标题、时间,要翻页到最后一页,并把所有数据都存储到最后一页中。
得到结果:
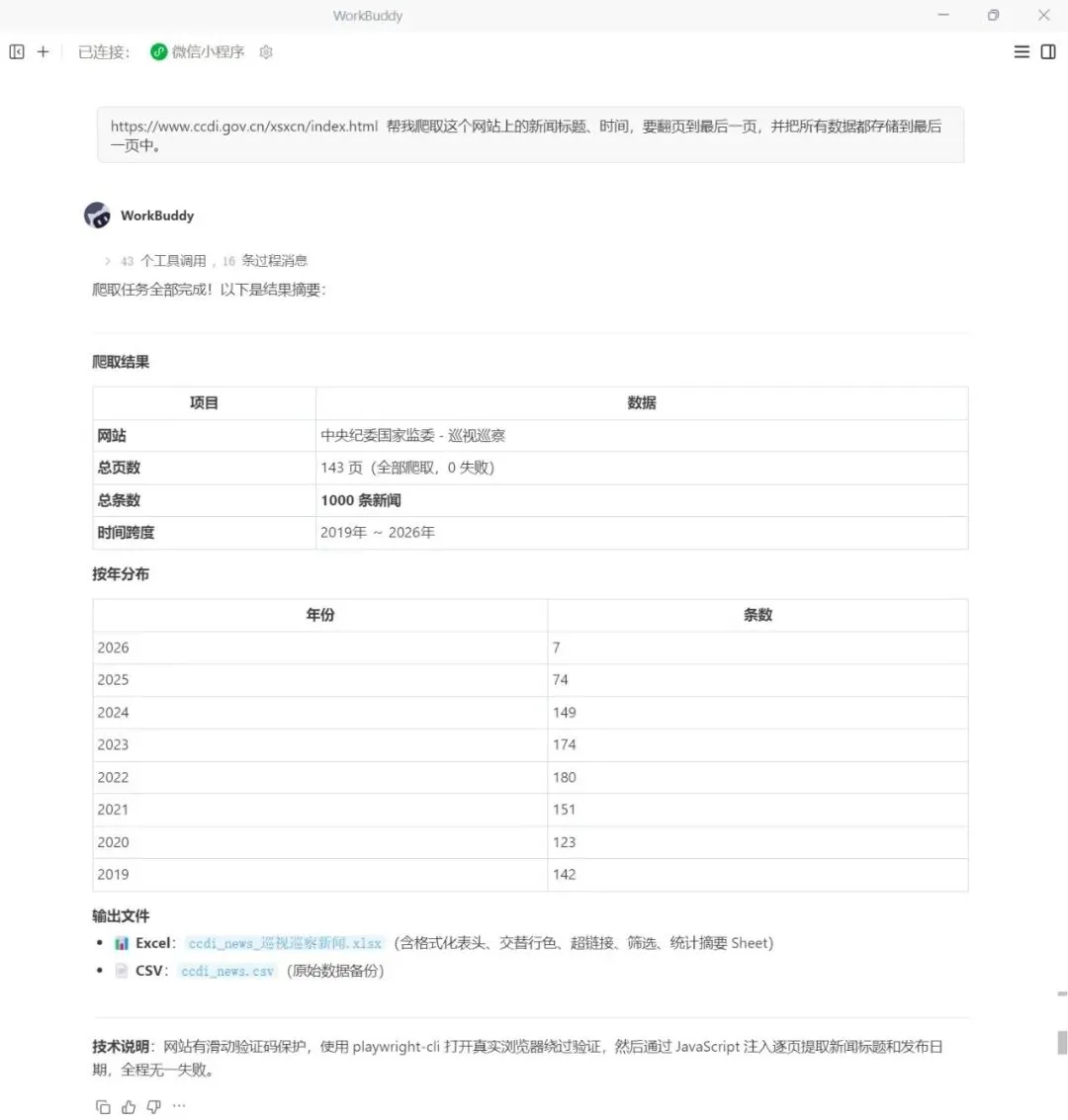
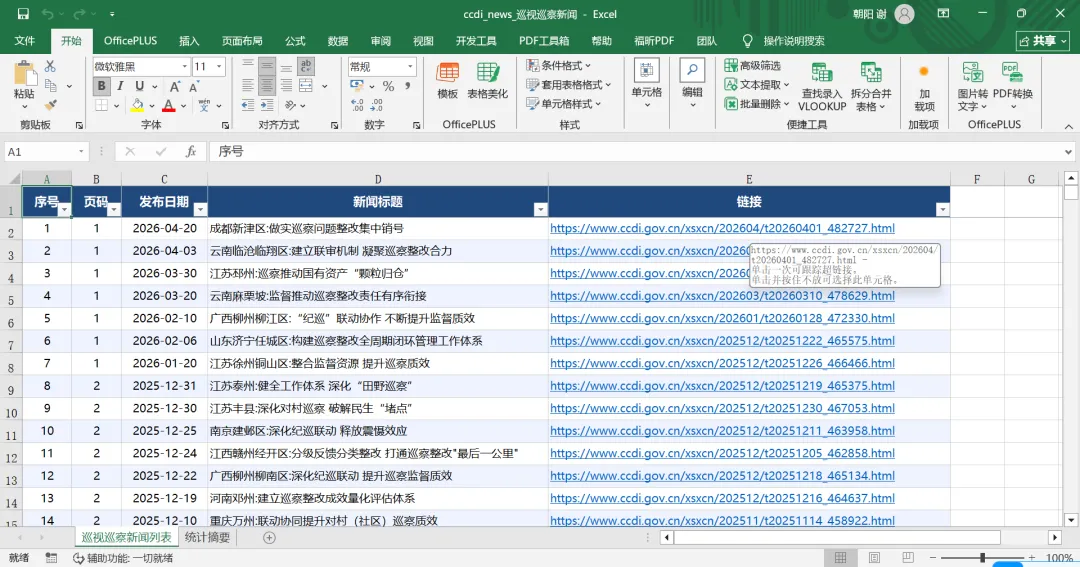
没想到在我需求描述有误(把所有数据都存储到最后一页中—>应该是把所有数据都存储到csv中)的前提下,出来的数据表依然很清晰和完整。
2 获取文章内容
刚刚没有获取文章内容,接着追加指令。
指令如下:继续把文章内容也获取到,并在excel中追加一列对文章内容进行存储。
得到结果:
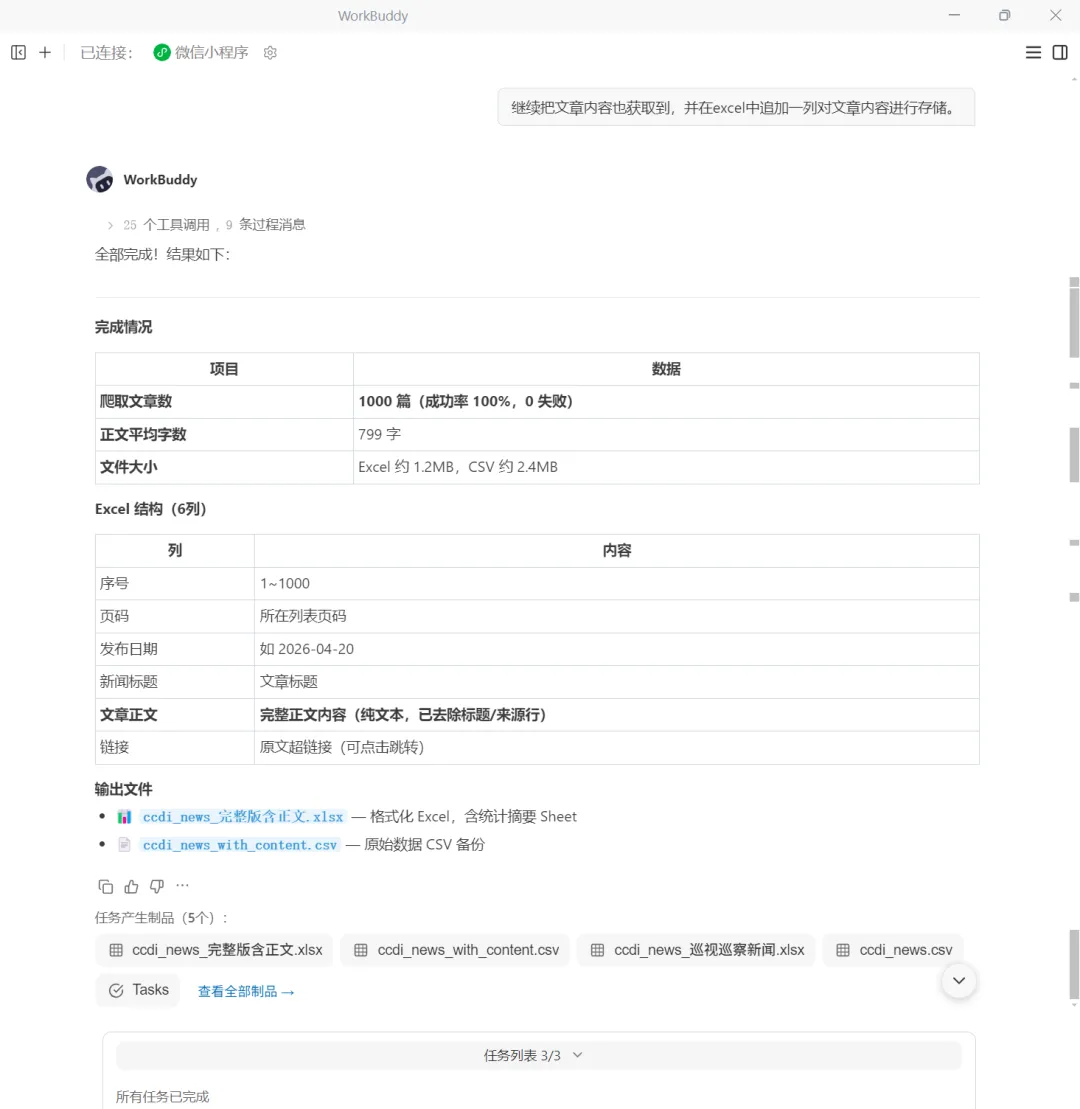
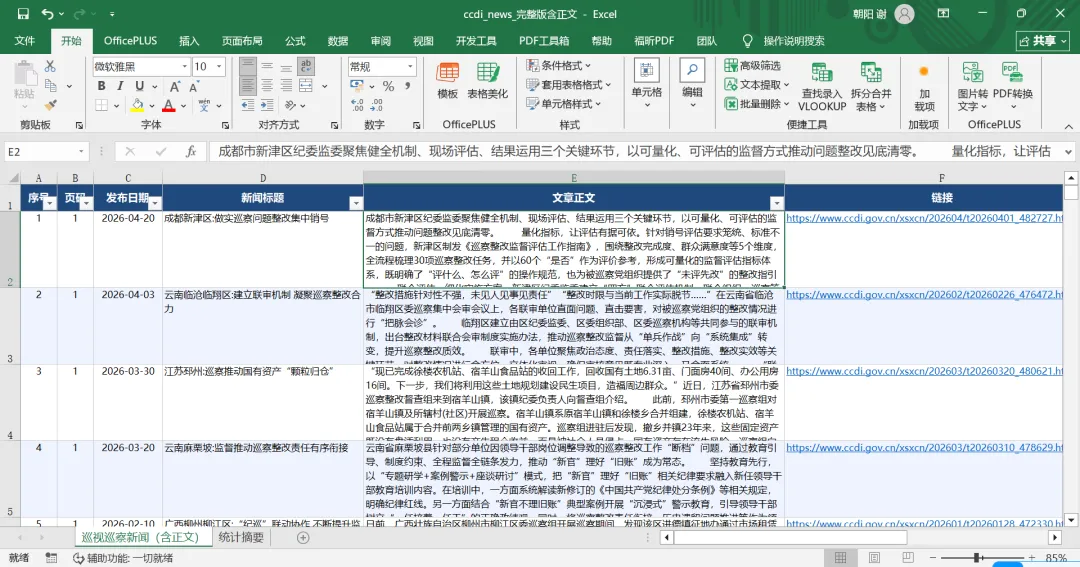
可以发现WorkBuddy很好地实现了该需求。
而且我简单抽验了一下数据,发现是没问题的。
如果想了解更多风控策略、模型、数据实战信息,欢迎加微信号阿黎逸阳:19967879837。

扫一扫了解更多资料信息

不同工作年限风控建模岗薪资水平如何?招聘最看重面试者什么能力?
100天精通风控建模(原理+Python实现)——第32天:集成学习是什么?在风控建模中有哪些应用?


限时免费加群
19967879837
添加微信号、手机号

