不用写代码就能爬网页?Scrapling内置MCP Server,让AI直接帮你抓数据
- 2026-06-23 10:50:54
字数 1976,阅读大约需 10 分钟
凌晨两点,爬虫脚本又挂了。某个网站改了三个 class 名,BeautifulSoup 全废了。
做过爬虫的都遇到过这种事,网站随便改个版,你的选择器就失效。
后来发现了 Scrapling,一个能自适应网站结构变化的 Python 爬虫框架。

跟 BeautifulSoup 和 Scrapy 不同,Scrapling 的核心思路是自适应:选择器不是死的,网站结构变了它能自动找回原来的元素。请求、浏览器自动化、反爬绕过全在一个库里。
目前这个项目开源半年,GitHub上收获 6万 Star,效果怎么样基本都不用验证了~!
安装与上手
安装只需要一行:
pip install scrapling装完就能用。最基本的抓取:
from scrapling import Fetcherpage = Fetcher().get('https://quotes.toscrape.com/')for quote in page.css('.quote'): print(quote.css('.text::text').get())如果需要绕反爬、用 StealthyFetcher,要先安装 Camoufox 浏览器:
scrapling install camofox这个命令会自动下载配置好反检测浏览器,之后就能用 StealthyFetcher 处理有保护的网站。
Automatch 自适应匹配
Automatch 是 Scrapling 最核心的功能。
原理不复杂:第一次选中某个元素时,Scrapling 把元素的「指纹」存到本地 SQLite,包括标签名、文本内容、属性、DOM 位置、父元素信息等。网站改版后,选择器返回空,加上 adaptive=True,Scrapling 从数据库捞出指纹,在新页面上跑相似度匹配,返回最像的那个元素。
这不是 AI,纯算法,不需要调 API,不消耗 token。
D4Vinci 在 dev.to 上给了一个例子。他用 Wayback Machine 拿 Stack Overflow 2010 年的页面和现在的页面对比。同一个选择器 #hmenus > div:nth-child(1) > ul > li:nth-child(1) > a(Chrome 自动生成的路径),在旧页面保存指纹,到新页面用 auto_match=True,Scrapling 照样把同一个按钮找回来了。
实际项目里这个能力很实用。我之前做价格监控脚本,目标站两个月改了三次布局。用 Scrapling,第一次选价格元素时 auto_save=True,后面就算 class 全换了,adaptive=True 还能定位到。
三种 Fetcher 抓取器
Scrapling 提供三种 Fetcher,从轻到重:
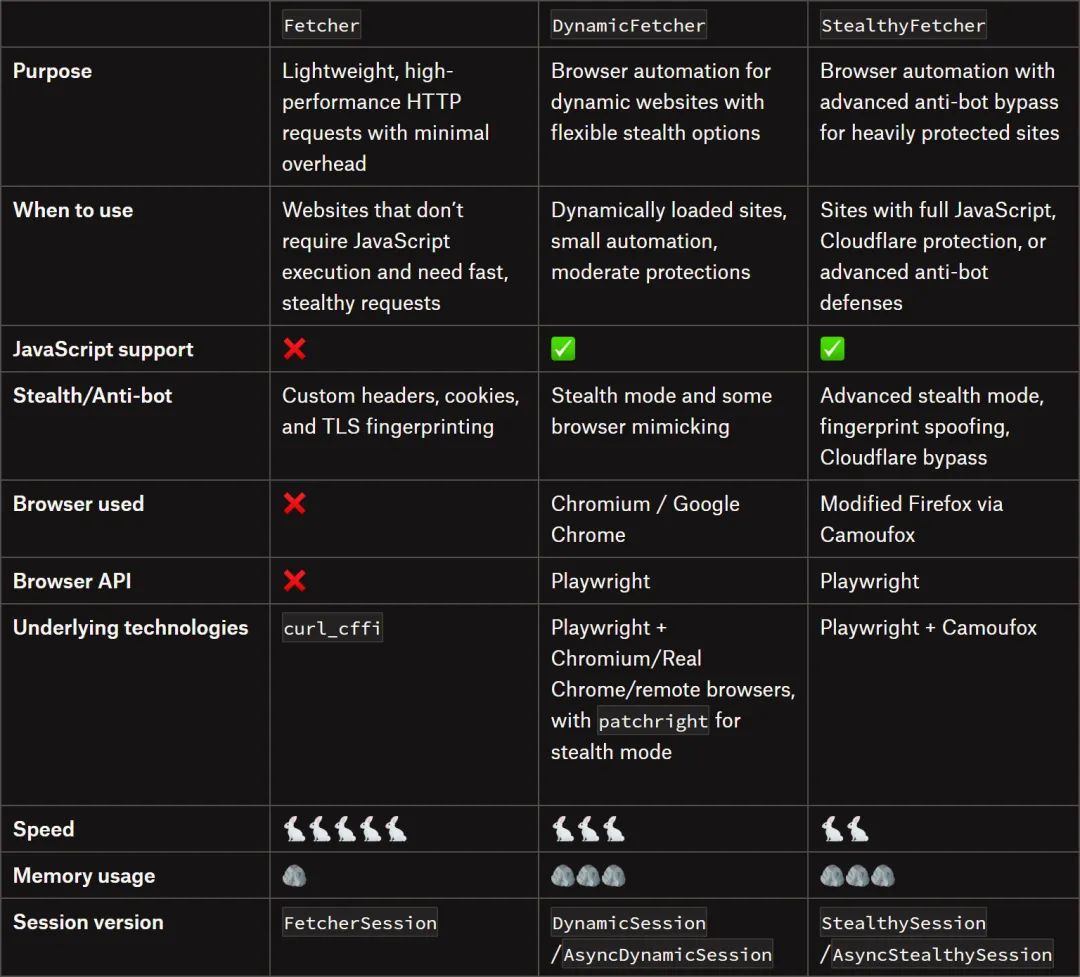
Fetcher:最基础的 HTTP 请求层,基于 curl_cffi,能伪造浏览器 TLS 指纹和 header,支持 HTTP/3。适合不需要 JavaScript 渲染的静态页面,没有浏览器开销,速度最快。
DynamicFetcher:基于 Playwright,启动真实的 Chromium 或本机 Chrome。处理那种数据靠 AJAX 加载、DOM 靠 JS 拼出来的页面。支持 wait_selector、network_idle 等参数。
StealthyFetcher:专门对付反爬。底层是修改版 Camoufox(基于 Firefox 的反检测浏览器),加上自己的隐身补丁。指纹伪装、鼠标轨迹模拟、从 Google 搜索跳转的 referrer,全内置。
三种 Fetcher 的 API 一样,换个类名就能切换。从 Fetcher 升到 StealthyFetcher 一般改两行 import。每种 Fetcher 都有对应的 Session 类维持长连接,支持 cookie 保持、并发和异步。
解析层也很灵活:
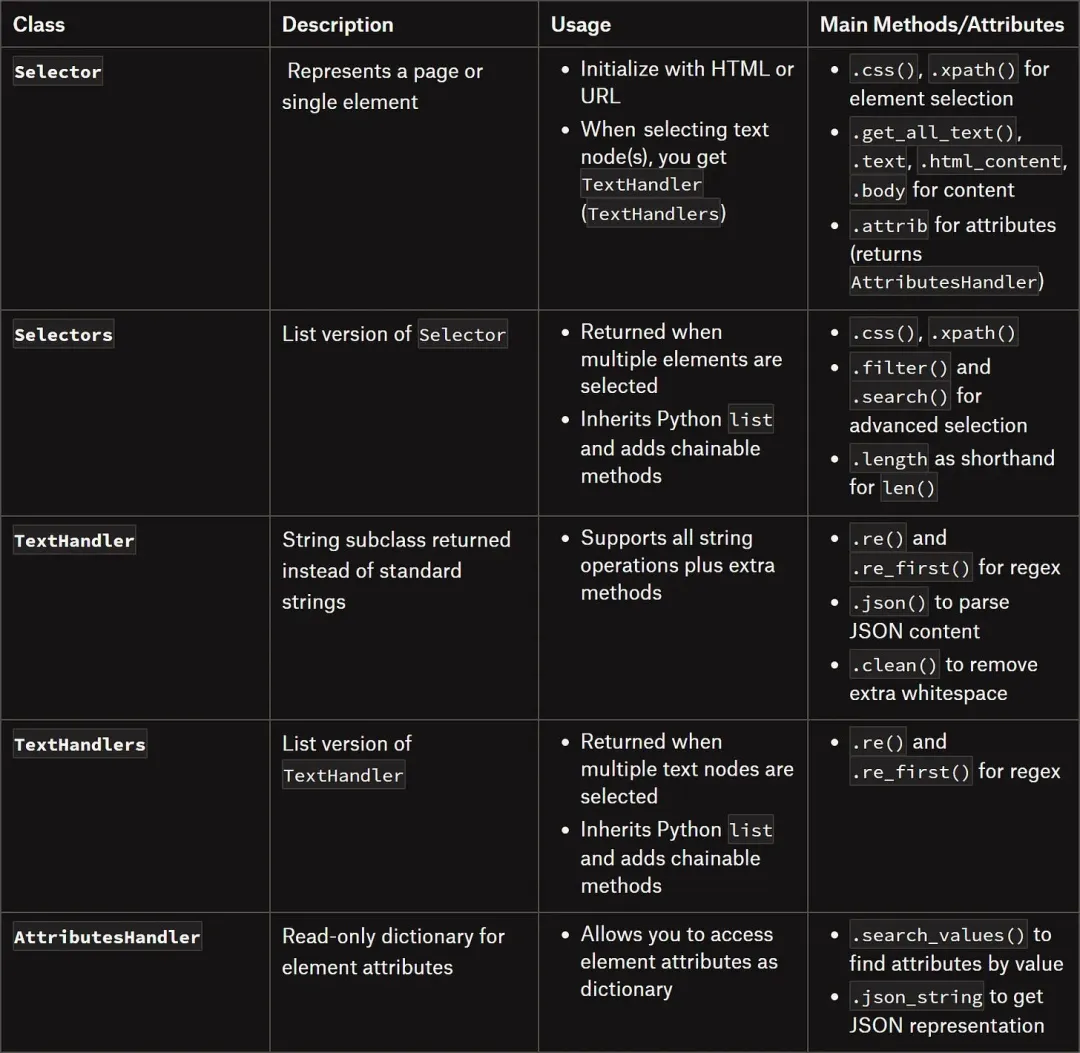
CSS 选择器、XPath、BeautifulSoup 风格的 find_all、按文本搜、按正则搜,五种方式全在一个 Response 对象上。写法跟 Scrapy 的 Parsel 类似,学过 Scrapy 的直接上手。
选择器支持链式调用:page.css('.quote').css('.text::text').getall(),不用写循环。css_first() 和 xpath_first() 比直接用 css() 快约 10%,底层做了短路优化。
绕过 Cloudflare
Cloudflare Turnstile 是爬虫最常见的门槛。传统方案是上 Playwright 硬刚,配上各种反检测补丁,维护成本不低。
Scrapling 的 StealthyFetcher 在框架层面处理了这件事。底层是修改过的 Firefox(Camoufox),加上隐身层:自动伪造浏览器指纹、模拟鼠标移动、把请求伪装成从 Google 搜索结果来的流量。不需要像 Playwright 那样手动配置 stealth 插件。
from scrapling.fetchers import StealthyFetcherpage = StealthyFetcher.fetch( 'https://nopecha.com/demo/cloudflare', solve_cloudflare=True, humanize=True, headless=True)data = page.css('#padded_content a').getall()solve_cloudflare=True 自动处理 Turnstile 挑战页面,humanize=True 让鼠标轨迹更像真人。这些都在 headless 模式下完成,大部分反爬方案在 headless 下效果会打折扣。
D4Vinci 自己说这不是万能钥匙,Cloudflare 的检测每天都在更新。但能在 headless 模式搞定 Turnstile,在同类工具里确实少见。
内置 Spider 框架
Scrapling 内置了一个类 Scrapy 的 Spider 框架,设计更轻:
from scrapling.spiders import Spider, Responseclass QuotesSpider(Spider): name = "quotes" start_urls = ["https://quotes.toscrape.com/"] concurrent_requests = 10 async def parse(self, response: Response): for quote in response.css('.quote'): yield { "text": quote.css('.text::text').get(), "author": quote.css('.author::text').get(), } next_page = response.css('.next a') if next_page: yield response.follow(next_page[0].attrib['href'])result = QuotesSpider().start()result.items.to_json("quotes.json")用法跟 Scrapy Spider 类似,但没有项目模板、settings.py、middlewares,一个脚本直接跑。
功能包括:并发控制、按域名节流、自动重试被拦截的请求、robots.txt 遵守(可开关)。
断点续爬很实用。按 Ctrl+C 后进度自动保存到 checkpoint,下次用同一个 crawldir 从断点继续。做大批量采集时能省很多事。
还支持多 Session 混用:同一个 Spider 配置多个 Session 类型,普通页面用轻量 FetcherSession 快速过,被保护页面自动切到 StealthySession,一个 sid 参数搞定。
性能数据
Scrapling 在 GitHub 仓库放了一套 benchmark,文本提取速度测试,5000 个嵌套元素跑 100+ 次取均值:
BeautifulSoup 慢了七百多倍。BS4 本来不靠速度吃饭,但差距到这个程度还是挺大。
Scrapling 和 Parsel 基本持平,底层有共用部分。元素相似度匹配上,Scrapling 比 AutoScraper 快 5 倍多(2.39ms vs 12.45ms)。
实际用下来,静态页面 Fetcher 抓取解析确实快。跑浏览器的那两种取决于页面复杂度,但 Scrapling 做了浏览器标签池复用,同一个 Session 内多次请求比每次新开浏览器快不少。
MCP Server
Scrapling 内置了 MCP Server,能让 Claude Desktop、Cursor 这类 AI 工具直接调用它爬网页。
直接让 AI 读原始 HTML 找数据,Token 消耗很大,而且 HTML 里导航栏、广告、脚本标签占了大量体积。Scrapling 的 MCP Server 让你在 prompt 里传 CSS 选择器,它先把目标元素提取出来,只把结构化的小块内容传给 AI。同样任务,Token 消耗可能降一个数量级。
命令行也能直接用:
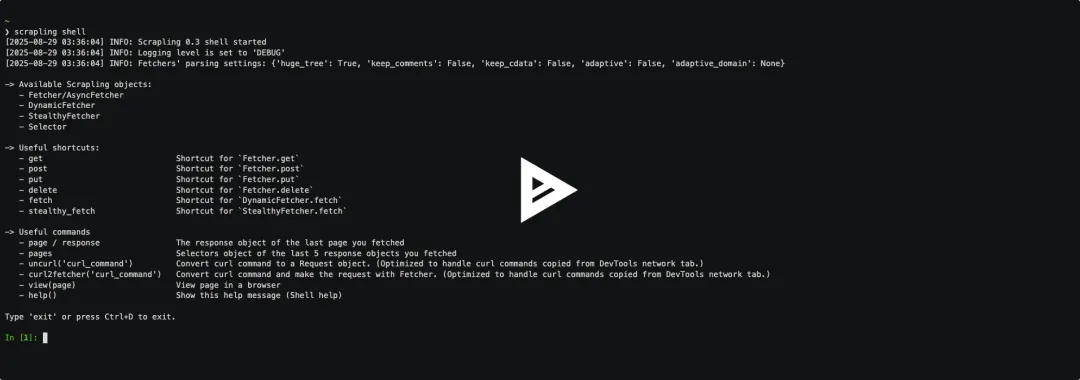
scrapling extract get 'https://example.com' content.mdscrapling extract stealthy-fetch 'https://nopecha.com/demo/cloudflare' captchas.html --solve-cloudflare不用写 Python 代码。还有一个交互式 IPython Shell,适合调试选择器和测试反爬策略。
适用场景与局限
用了 Scrapling 一段时间,我的判断是:它在轻量静态抓取和 Scrapy 重型集群之间找到了一个合适的位置。
爬几个目标站做监控,站点偶尔改版,不想每周修选择器,这是 Scrapling 最对口的需求。目标站有 Cloudflare 保护,不用自己搭 Playwright 反检测也能搞定。把爬虫能力嵌入 AI agent(Claude Code 的 skill 或 MCP 工具链),Scrapling 的 MCP Server 能顶上。小到中型数据采集足够用,不需要上 Scrapy 分布式架构。
几十万页的大规模分布式爬取就算了,Scrapy 的生态和中间件更成熟。也别当无头浏览器自动化测试工具用,这毕竟是爬虫框架。Serverless 环境里用自适应功能会踩坑,指纹存在本地 SQLite,Lambda 这种无状态环境每次跑完数据就没了,需要自己处理持久化。
创始人自己也说了,Scrapling 不是为了取代 Scrapy,是为了让你面对难啃的网站时不用那么累。
现在 6 万 star,92% 测试覆盖率,Docker 镜像自动构建,文档齐全。对一个才出来一年多的项目,成熟度已经不错了。
如果你也在为爬虫维护头疼,可以试试 Scrapling。
GitHub地址:
https://github.com/D4Vinci/Scrapling

