今天介绍利用fa2.0获取网页源码教程,这是也是一个利用lua代码获取源码的方法!
🌟方法一🌟
获取内容 get函数
Http.get(url,code,content,header,callback)
向服务器发送数据 post函数
Http.post(url,data,code,content,header,callback)
下载文件 download函数
Http.download(url,path,content,header,callback)
url 网络请求的链接网址
code 使用的code,也就是服务器的身份识别信息
charset 内容编码
header 请求头
callback 请求完成后执行的函数
data 向服务器发送的数据
回调函数接受四个参数值分别是
code 响应代码,2xx表示成功,4xx表示请求错误,5xx表示服务器错误,-1表示出错
content 内容,如果code是-1,则为出错信息
cookie 服务器返回的用户身份识别信息
header 服务器返回的头信息
➖➖➖➖➖➖➖➖➖➖➖➖➖➖
Http.get("https://m.baidu.com/","utf8",function(状态码,源码)
if 状态码==200 then
tx.setText(源码)
end
end)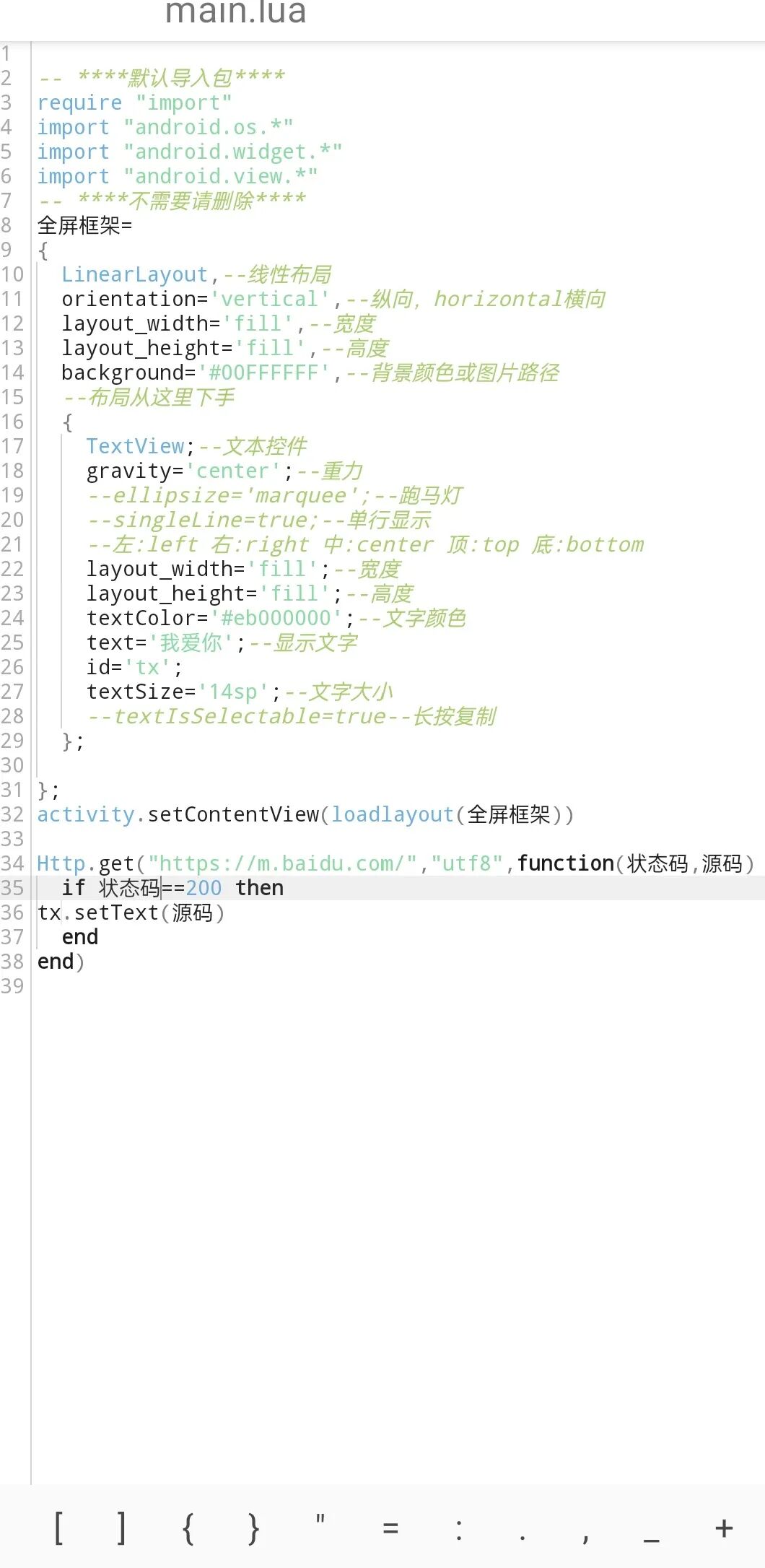

以上是效果图
➖➖➖➖➖➖➖➖➖➖➖➖➖➖
🌟方法二🌟
此方法为获取加载内容后的源码,此方法比较容易抓去到网页内容!!
llq.loadUrl("https://m.baidu.com/")
--这里需要利用浏览器先加载网页,等加载完成再获取完整网页源码
llq.setWebViewClient{
onPageFinished=function(view,url)
--网页加载完成
llq.evaluateJavascript("function getSource(){return \"<html>\"+document.getElementsByTagName('html')[0].innerHTML+\"</html>\";};getSource();",{
onReceiveValue=function(源码内容)
-- %转换为%;再转换回%,是为了将\\n转换为%n,而这是为了让\\n能够正常转换为\n而不是\。
源码内容=源码内容:gsub("%%","%%;"):gsub("\\\\n","%%n"):gsub("\\n","\n"):gsub("%%n","\\n"):gsub("%%;","%%"):gsub("\\u003C","<"):gsub("\\\"","\""):gsub("^\"",""):gsub("%%s","")
tx.setText(源码内容)
end
}
)
end
}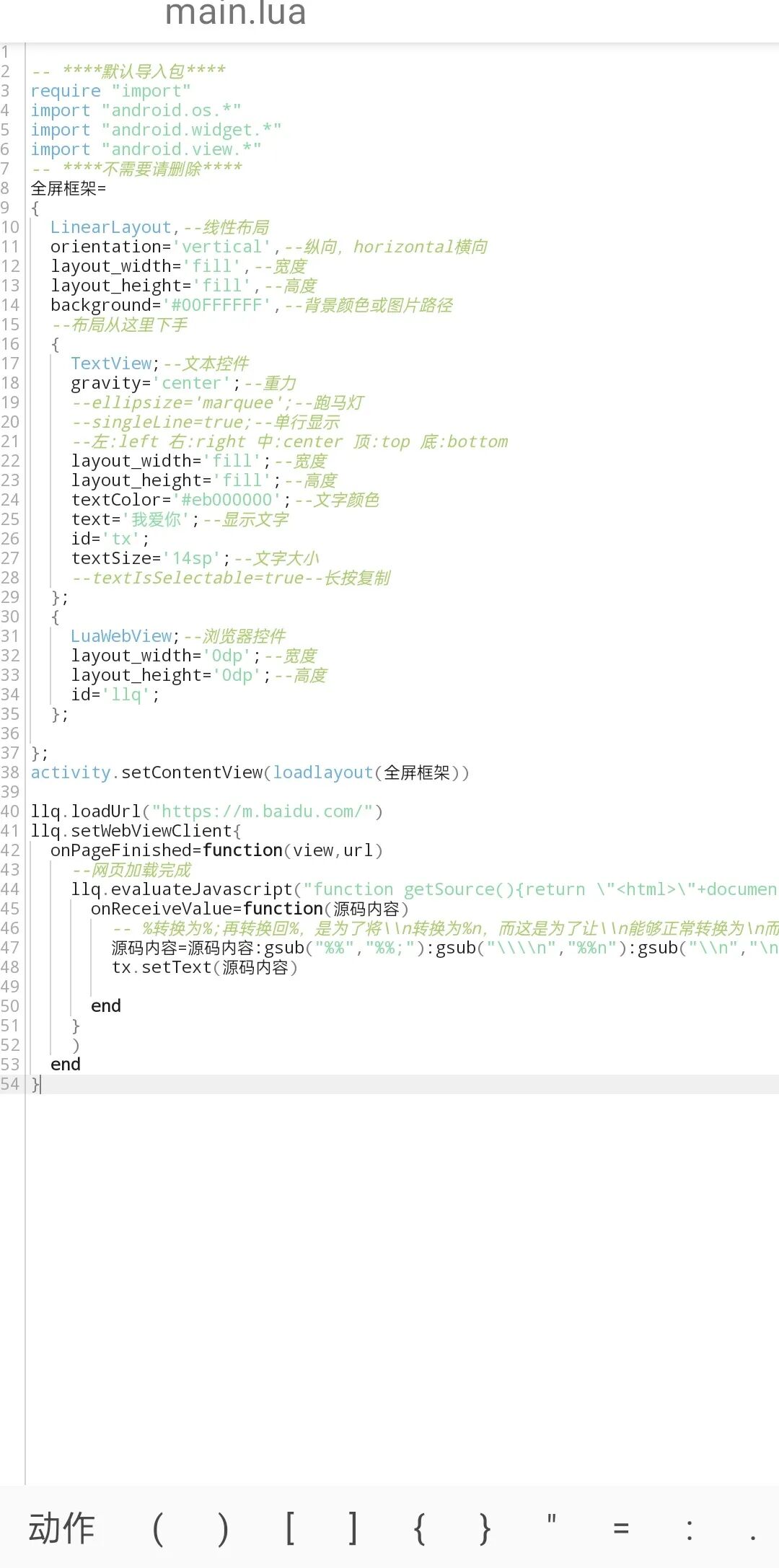

效果图
➖➖➖➖➖➖➖➖➖➖➖➖➖
先写到这,获取网页源码后就可以做爬取内容了!下期再讲,多谢关注分享支持!!
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
