1. 为什么今天必须关注它
“AI 生成网页”不是新词,但大部分人对它的理解,可能还停留在“让模型写一份 HTML/CSS”。这当然有用,但离真正可用、好看、协调的页面还差很远。因为今天的网页并不是纯代码产物,它天然是多模态的:要有图、可能有视频、常常有图表,甚至要处理整体风格、模块关系和视觉层级。
MM-WebAgent 今天值得写,就在于它不是在继续卷“谁代码更强”,而是在问一个更像真实产品设计的问题:当图片、视频、图表都可被原生生成时,网页生成该如何变成一个真正的 Agent 问题?
2. 它到底做了什么
这篇论文的基本判断非常对:过去的网页生成系统,往往把多模态元素当成“外挂”。先写页面,再找图;或者用占位符顶上去;或者让不同工具各干各的。结果就是三个常见问题:风格不统一、尺寸几何不匹配、拼起来以后全局很散。
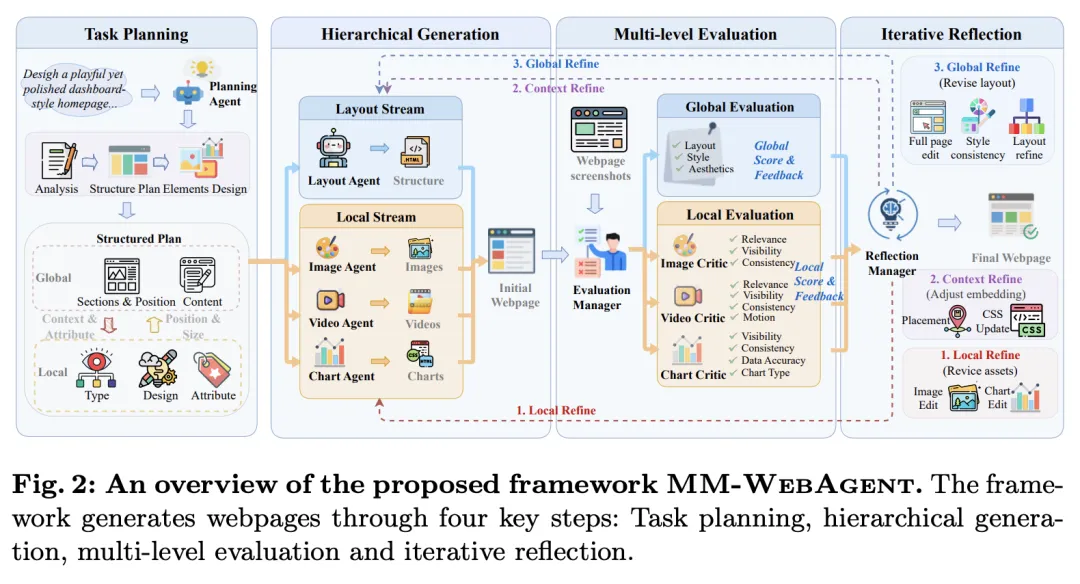
MM-WebAgent 的思路是,把网页生成重写成一个层级化的计划—生成—反思流程。它先做全局布局规划,决定页面分区、顺序、层次和风格属性;然后为每一个多模态元素生成局部计划,明确这个图、视频或图表在页面中的角色、上下文、尺寸约束和风格指导;最后再做三级反思:局部修元素、上下文修 HTML/CSS、全局修版式和风格。
3. 方法/系统的关键机制拆解
这套系统里最重要的不是“调用了多少生成模型”,而是它把不同类型的生成动作纳入了统一 Agent 框架。全局规划负责的是网页结构,局部规划负责的是元素内容,执行阶段则按工具类型生成图像、视频、图表,再把这些原生资产插回网页中。这样一来,多模态内容不再是附属品,而是页面结构的原生组成部分。
更有意思的是反思机制。作者把 reflection 分成三层:第一层是 local refine,改单个元素本身;第二层是 context refine,改周边 HTML/CSS,解决溢出、对齐、留白等集成问题;第三层是 global refine,直接结合网页代码和渲染截图,回头修整体布局平衡和风格统一。
这其实非常像人类设计师的工作流:先搭版,再填素材,再来回调。也正因为如此,这篇论文最有价值的地方不只是性能,而是它给“设计型 Agent”提供了一个更合理的系统范式。
4. 它和过去工作的本质区别
过去大量 WebGen 工作更偏 code-first:让模型尽量多写正确代码,页面视觉往往靠现成组件或占位符勉强撑住。MM-WebAgent 则显式提出:网页生成不只是代码问题,而是一个多模态协同问题。
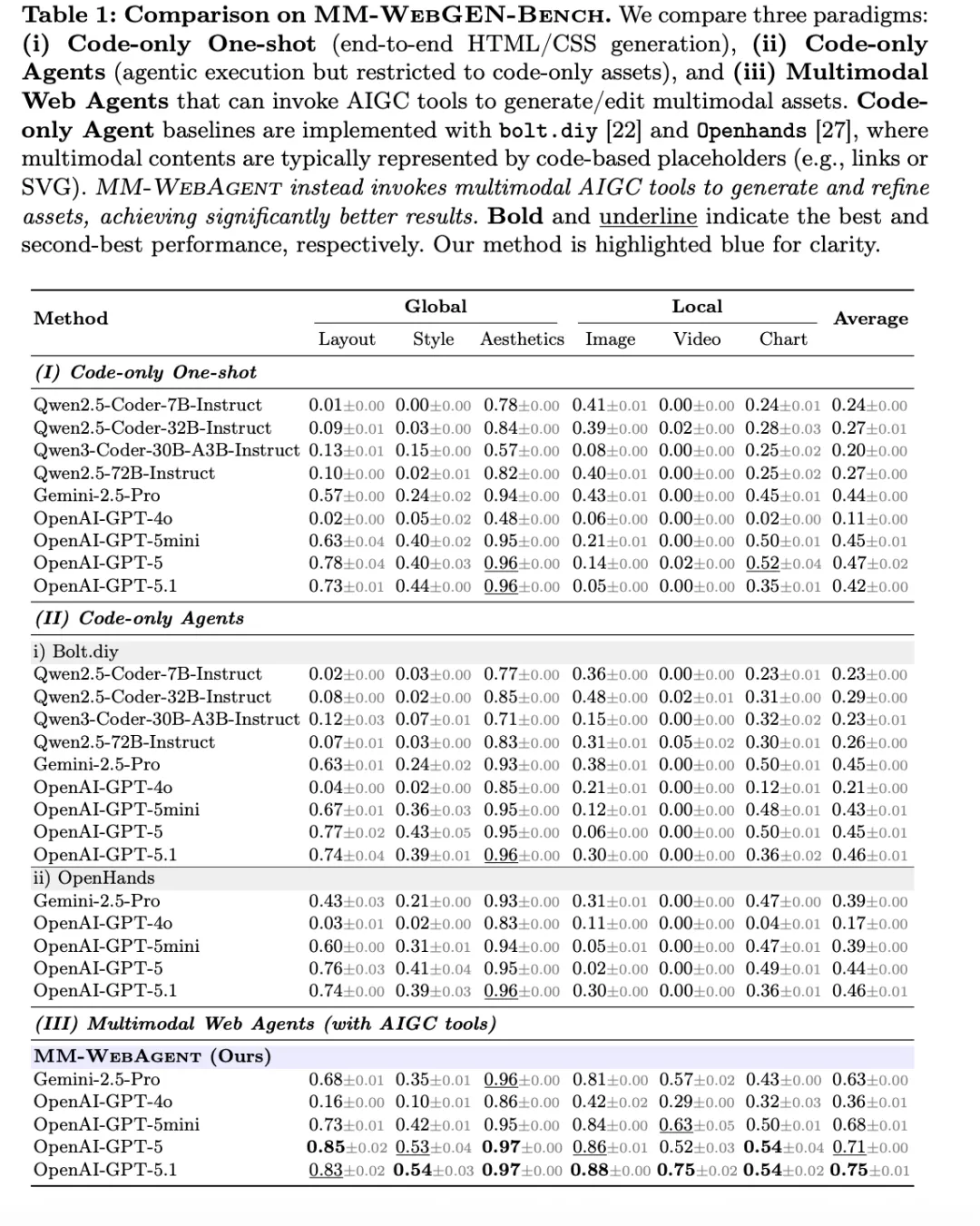
作者还专门做了一个很关键的消融:单纯把 AIGC 工具接进 code-only pipeline,整体分数只从 0.42 提到 0.45;而完整的 MM-WebAgent 可以到 0.75。这意味着提升并不是“工具多了”,而是“工具被放进了正确的 Agent 结构里”。
5. 最值得注意的实验或案例
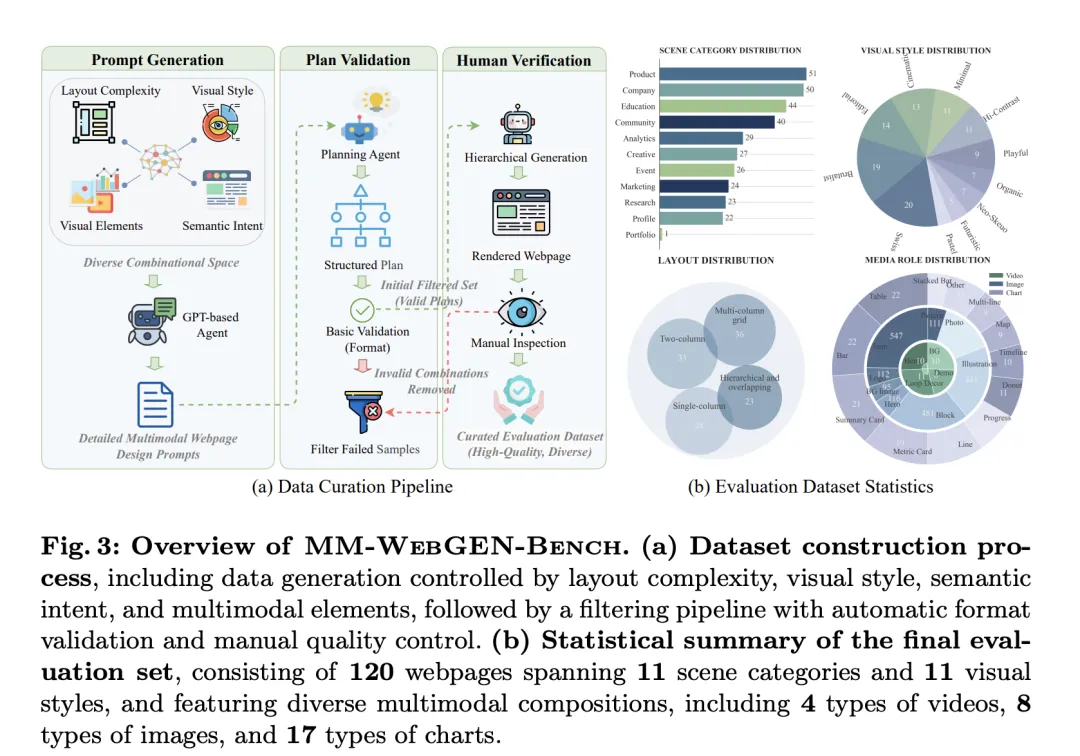
这篇文章最值得传播的实验有两个。第一,在自建的 MM-WebGEN-Bench 上,完整系统拿到 0.75 的平均分;在 OpenAI GPT-5.1 配置下,图像、视频、图表等局部多模态指标都显著强于 code-only 和 code-agent 基线。比如在主表里,GPT-5.1 版本的 MM-WebAgent 平均分 0.75,而 code-only GPT-5.1 是 0.42。
第二,在更偏功能性的 WebGen-Bench 上,它虽然不是专门为后端逻辑而设计,仍拿到与最强基线并列的 55.4 accuracy,而 appearance score 还略高。这说明它不是只会做“好看 demo”,而是在更广义网页生成里也有竞争力。
作者还给出了效率数据:系统平均每任务约 155.8 秒,与 OpenHands 的 182.4 秒 在同一量级,尽管它处理的是更复杂的原生多模态生成。用户研究里,MM-WebAgent 对比其他方法的赢率接近 79%。
6. 我认为这项工作的真正价值
我的判断是:这是一篇强工程、但方向很对的论文。 它未必意味着“网页设计被自动化了”,但它很清晰地指向了一个趋势——未来的 Web Agent 不会只是代码执行器,而会变成一个协调不同模态、不同工具、不同设计目标的“页面总控”。
这背后其实有很强的产品想象力。今天很多企业的落地页面、活动页、数据页,最大成本不是“写不出代码”,而是“做出来不协调”。如果一个 Agent 真能同时处理布局、视觉素材、图表表达和最终一致性,那它影响的可能不只是前端工具,而是低门槛 Web production 的整条链路。
7. 它的不足与争议点
但这篇工作也有明显边界。第一,它当前的强项更偏展示型、内容型网页,而不是复杂业务逻辑网页。第二,它的成本并不低,表里给出的单任务平均成本在 3.21 美元 左右,这对研究 demo 可以接受,对大规模生产还得再降。第三,它目前相当依赖强模型和外部生成工具,这意味着复现门槛、落地门槛都不低。
所以它更像是在证明一件事:多模态网页生成这件事,值得被 Agent 化。 但离真正工业级的低成本、高可靠自动建站,还有距离。
8. 对 Agent / MLLM 未来的启发
这篇论文给我的最大启发是:Agent 的“动作空间”正在扩大。 以前我们说 Agent 会点按钮、调 API、写代码;现在这篇工作告诉你,生成图片、生成视频、生成图表,也可以成为 Agent 的原生动作。
一旦这个方向走通,后面会发生什么?可能是自动化落地页生成;可能是多模态 BI 页面自动搭建;可能是“需求文档 → 可用页面”的真正一站式闭环。而这类产品的核心,不会只是基础模型,而是规划、约束、反思和多工具协调。这正是 MM-WebAgent 的范式价值。
9. 总结收束
如果 DR³-Eval 代表的是“研究型 Agent 的考试基础设施”,那么 MM-WebAgent 代表的就是另一件事:当多模态资产生成成为常态,网页生成正在从代码问题,升级成 Agent 设计问题。 这篇稿子非常适合今天发,因为它既新鲜,也有很强的产品想象空间。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
