网页智能体,怎么就卡住了?
说到让 AI 帮你操作网页,很多人第一反应是"这不是已经能做了吗?"——各类截图识别、元素定位的方案确实不少。但说实话,目前主流的网页智能体用起来,体验并不能算好。
原因很简单:大多数方案走的是"截图或 DOM → 预测下一步动作"的路子。什么意思呢?就是 AI 每一步都要先看一眼当前页面长什么样,然后决定"该点哪里""该输入什么""该不该滚动"。每做一件事,就重复一次这个流程。
这听起来没毛病,但问题在于,网页操作天然是多步骤的。你要注册一个账号,可能需要:填用户名、设密码、选生日、勾同意、点提交——五个步骤。用"逐步预测"的方式,AI 得猜五次,每猜一次都有出错的可能。而且这种低级动作预测,没法表达"把整个表单填完"这种复杂意图。更要命的是,一旦中间某步猜错了,后面的步骤基本全废。
我的理解是,这本质上是一个"动作粒度"的问题——你让 AI 在太细的粒度上做决策,它就很难处理长链条、有逻辑依赖的任务。
微软的解法:别点鼠标了,直接写代码
微软研究院本月发布的开源框架 Webwright,思路和上面说的完全不同。
它的核心理念可以用一句话概括:让 AI 在终端里写 Playwright 代码,而不是一步一步地点鼠标。
Playwright 是微软自己家的浏览器自动化库,你用 Python 或 JS 写几行脚本就能控制浏览器自动填表单、点按钮、截页面。Webwright 的做法是,让大模型直接生成 Playwright 脚本,然后在终端里跑,跑完看结果,发现报错就改代码再来一轮。
打个比方:传统的网页智能体就像你遥控一个人去操作网页,每一步都要告诉他"现在点右上角那个蓝色按钮"。而 Webwright 是直接给那个人一台电脑,让他自己写个脚本来自动化完成。后者效率高得多,因为一个脚本就能把一整套操作串起来。
而且代码天生支持循环、函数、条件判断这些抽象能力。比如"在五个页面上重复同样的操作",写个 for 循环就行,比让 AI 一遍一遍预测点击省事太多了。
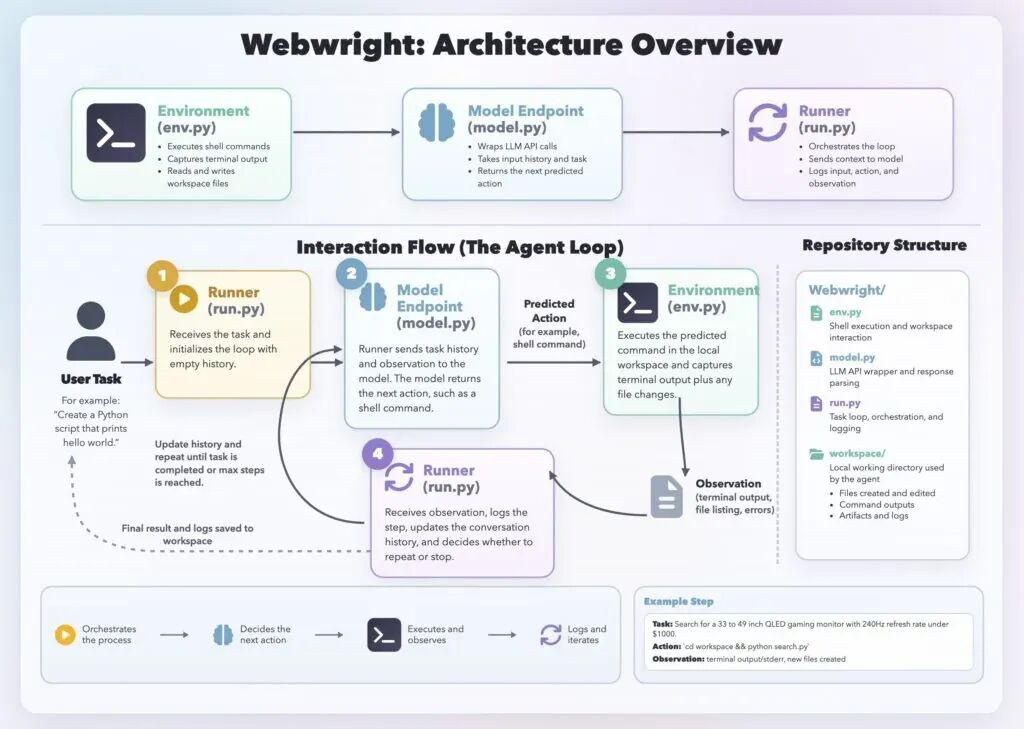
三个组件,加起来一千行
Webwright 的架构极其精简,只有三个核心组件:
- Runner(约 150 行代码):负责整个流程的调度,把当前上下文发给模型,拿到模型返回的思考和命令,然后交给环境执行。
- Model Endpoint(约 550 行代码):和模型 API 对接的接口层。
- 终端环境(约 300 行代码):负责执行命令,返回终端输出、日志、截图或错误信息。
三个加起来大概 1000 行代码。没有多智能体编排,没有分层规划,没有各种花里胡哨的中间件。
这在当下动不动就"多 Agent 协同""复杂编排"的 AI 工具圈里,算是一股清流了。我觉得这种极简设计反而是一个聪明的选择——框架越简单,模型的能力就越直接地体现在结果上,调试也更容易。你要是出了 bug,看 1000 行代码总能找到问题在哪。
执行流程也很直观:Runner 把上下文给模型 → 模型返回思考内容和一条 shell 命令 → 环境执行命令并返回结果 → 进入下一轮。就这样循环,直到任务完成。
两个工程难题,微软是怎么解的
当然,让 AI 写代码来操作网页,听起来美好,实际落地会碰到两个很实际的坑。
第一个坑:AI 容易"过早交卷"。
模型跑着跑着,可能还没真正完成任务,就信誓旦旦地说"我搞定了"。这在 LLM 场景里太常见了——模型天生想让你开心,所以倾向于说"做完了"。
Webwright 的解法是加了一个门控步骤:模型声称完成之后,必须先生成一个自检配置,然后在一个全新的干净文件夹里重新跑一遍最终脚本。跑完之后,结合日志和截图,让模型自己再判断一次——到底成功了没有。只有通过了这轮自检,才会输出完成标记。
说白了就是"你说做完了?那从头跑一遍证明给我看"。这招挺实用的。
第二个坑:对话历史太长,上下文爆炸。
复杂任务可能要跑几十步甚至上百步,每一步都有终端输出、日志、截图。这些全部塞进上下文窗口,很快就会超限。
Webwright 的做法是每 20 步做一次压缩——把之前的历史记录总结成一份摘要,替换掉原始内容。这样上下文长度就能控制住。当然,压缩必然会丢失一些细节,但在实际测试中,这个 tradeoff 是值得的。
跑分:GPT-5.4 + Webwright = 大幅领先
光说架构好不行,最终还得看成绩单。Webwright 在两个主流基准测试上都交出了不错的答卷。
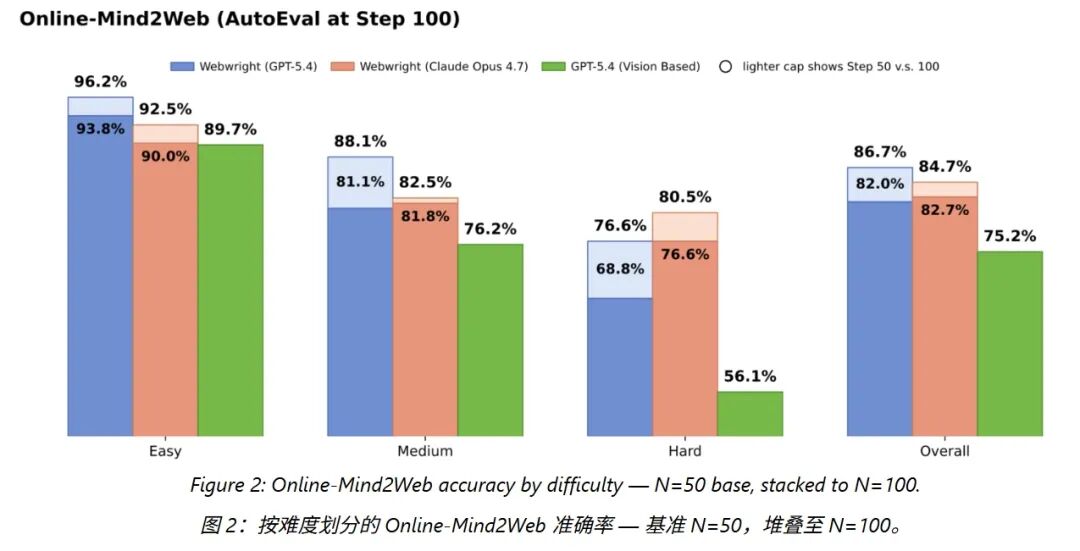
Online-Mind2Web:这个测试包含 300 个任务,覆盖 136 个常用网站,是网页智能体领域的"标准考试"。基于 GPT-5.4 的 Webwright 拿到了 86.67% 的整体准确率,在 100 步预算限制下,排进了公开方案的前列。
Odysseys:这个测试更难,关注的是跨多个网站的长链路浏览任务,平均每个任务指令有 272 个词。2026 年 4 月这个榜单上的最佳模型是 Opus 4.6,得分 44.5%。而 Webwright 搭配 GPT-5.4 达到了 60.1%,相对之前最好成绩提升了 35.1%。
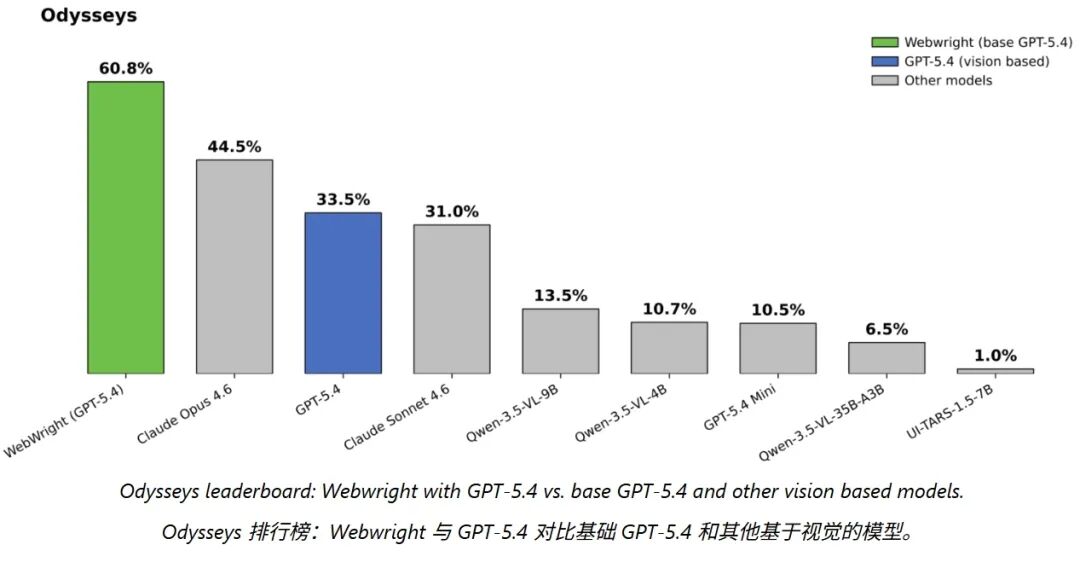
更直观地说,裸跑的 GPT-5.4 在这个测试上只有 33.5% 的得分。加上 Webwright 框架之后跳到了 60.1%,提升了 81.49%。这个提升幅度,老实讲,相当夸张。
个人看法,这个结果说明了一件事:对于复杂网页任务,怎么用模型比模型本身有多强更重要。同样是 GPT-5.4,换一种使用方式(从"逐步预测动作"变成"生成代码"),效果就天差地别。
我怎么看:简单粗暴,但方向对了
我觉得 Webwright 最有意思的点,不在于它用了什么新技术,而在于它验证了一个思路——让大模型用编程的方式来操作网页,比让它模仿人类点击更高效。
这其实符合一个更大的趋势:AI Agent 的进化方向,正在从"模拟人类低级动作"转向"利用编程能力完成高级任务"。毕竟代码是计算机的母语,让 AI 用自己的语言和计算机打交道,比让它假装成一个拿着鼠标的人,效率高得多。
当然,1000 行代码的框架也有它的局限。比如对动态渲染很强的页面(大量 JS 交互)、需要验证码的场景、需要登录态的复杂操作,这些都会是挑战。而且目前测试主要基于 GPT-5.4,换到其他模型上表现如何,还需要社区验证。
作为微软研究院出品的开源项目,Webwright 已经给了一个很好的起点。如果你对 AI Agent 感兴趣,或者正好在做网页自动化相关的工作,花半小时看看它的源码(反正才 1000 行),我觉得是值得的。
GitHub源码 地址:https://github.com/microsoft/Webwright
大家好,我是一直在准备跑路搞 AI 的奇菲特。 关注「AI奇菲特」,让 AI 成为你的杠杆!

